

What does it mean to work with data? Well, there are many different operations that could be performed with them including data collection, preprocessing, cleaning, uploading and it’s also good to see the entire data flow in some kind of report. Wouldn’t it be great to automatically trigger those operations just on defined time and all the processes get executed in order? Well, there’s one efficient tool that can do this job for you.
Apache Airflow is an open-source workflow management platform originally created by Airbnb. Now it’s a Top-Level Apache Software Foundation project since early 2019. It’s used to programmatically define, schedule, monitor and manage your workflows via robust and modern Airflow user interface build on the top of Flask. Airflow will make sure that each task will get executed in the correct order with all required resources. You always have full insight into the status and logs of completed and ongoing tasks. You may find this tool useful whether you are Data Scientist, Data Engineer or Software Engineer.
Apache Airflow is designed under the principle of „configuration as code“. It’s written in Python which allows you to import libraries and classes so you’re empowered to maintain full flexibility of your workflows. Anyone with Python knowledge can deploy a workflow. Apache Airflow does not limit the scope of your pipelines, you can use it to build ML models, transfer data, manage your infrastructure and much more.
It also provides many plug-and-play operators that are ready to execute your tasks on Google Cloud Platform, Amazon Web Services, Microsoft Azure and many other third-party services. This makes Airflow easy to apply to current infrastructure and extend to next-gen technologies.
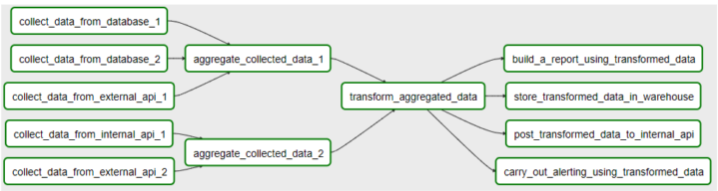
Workflows are defined using Directed Acyclic Graphs (DAGs), which are composed of tasks to be executed along with their connected dependencies. Each DAG represents a group of tasks you want to run, and they show relationships between tasks in Apache Airflow’s user interface. A DAG defines how to execute the tasks, but doesn’t define what particular tasks should do. You need to define functionality for each of your task in workflow.
There are four main components of Airflow’s architecture:
1. Scheduler – task initialization
2. Web server – user interface
3. Database – metadata storage
4. Executor – defines how work will be done
There are different types of executors to use for different use cases. SequentialExecutor can execute a single task at any given time, but it can’t run multiple tasks in parallel. LocalExecutor enables hyperthreading and paralelism. CeleryExecutor is used to run distributed Airflow cluster and KubernetesExecutor calls the Kubernetes API to make a temporary pods for each task instance to be run.
Apache Airflow serves well in many scenarios thanks to it’s ability to connect to different data sources, APIs and data warehouses. Beyond of others, it’s also suitable for training of the machine learning models.
And that’s all for today.
Hope it was interesting reading 🙂
Štefan Mastiľák